이거 제가 언급하던 Stable Diffusion 2.X 버전하고는 차별화된 진정한 최신 버전이란 것부터 언급하겠습니다. 이게 4월달에 베타버전이 나왔고 고작 2주 전에 0.9 정식 버전을 출시한 겁니다!!! 일단 근본부터 완전히 차이가 나는 게 우리가 쓰는 SD 1.5 버전이 기본 학습 및 생성 이미지가 512 x 512이고 2.1로 가봐야 768입니다. 그런데 SDXL은 XL답게! 기본 이미지 해상도가 무려 1024x1024 입니다! 진짜 엄청나죠. 업스케일둥절?
이 비교 이미지부터 보시죠.

1.5, 2.1 버전도 아니고 4월달 출시했던 SDXL 베타랑 0.9 버전이 이 정도 차이를 보입니다. 프롬프트도 보시면 심플한데 저 정도 퀄의 이미지를 단박에 뽑아냈다는 겁니다. 모델의 차원이 다른 걸로 보입니다. 신경망 파라미터 수도 오픈소스 중 당연 원탑이고, 기본 모델, 앙상블 모델 두 개가 상호작용해서 결과물 뽑는다네요. (어? 같은 건지는 모르겠는데 GPT4도 모델 8갠가? 같이 상호작용해서 그 답변 퀄을 뽑아낸다고 합니다.)
아무튼 당장 해봐야죠? 아래 주소로 가보세요.
저기 가서 곧바로 SDXL 0.9 테스트 때려볼 수 있습니다. 퀄리티가 어떤지 일단 감을 잡아보시길. 근데 무한정 공짜도 아니고(이미지 받으면 워터마크도 찍힘;;), 역시 제대로 커스터마이징해서 이거저거 테스트하려면 내 컴터에서 돌려야겠죠?
시스템 요구사항도 최소 VRAM 8GB 정도로 크지 않습니다. (요건 솔직히 좀;;;;) 아무튼 중요한 건 SDXL 0.9 또한 로컬에서 Web UI 방식으로 Demo 돌릴 수 있는 방법이 있다는 거~
아주 쉽습니다. 차근차근 따라오세요. windows 10, rtx3060 12gb, cuda 11.3 기준입니다. 아마 xformers 설치하셨으면 이미 cuda도 설치하셨으리라 믿습니다!
이번 거는 https://www.youtube.com/watch?v=__7VNmnn5iU&t=124s&ab_channel=SECourses 요분 자료를 기반으로 합니다. 가셔서 이분 구독하세요. 카페보다 나을지도....ㅋㅋㅋ
1. 준비
혹시 아직 설치를 안 하셨다면? python하고 git부터 설치하시기 바랍니다. 설치 방법은 첫 튜토에도 있고 그리 어렵지 않습니다~ 환경변수 설정에만 주의해주세요~ 그다음 허깅페이스huggingface 가서 가입하고 로그인해주세요~
허깅페이스는 인공지능 업계의 테슬라라고 보면 됩니다. ㅋㅋㅋ 아무튼 뭐 이거저거 라이브러리 개발하고 관련 서비스 제공해서 인공지능 발전에 큰 기여하고 있는 곳이니 가입해주셔용~
그다음 아래 주소가서 terms and conditions 가서 동의accept버튼 눌러주세요~
https://huggingface.co/OwlMaster/gg
https://huggingface.co/OwlMaster/gg2
연구목적으로만 사용하겠다는 뭐 그런 겁니다.
그다음 아래주소로 가서 허깅페이스 access token을 생성하고 복붙해둡니다. api 같은 거 쓸 때 사용자 식별하는 용도로 쓰는 겁니다. 아디비번같은 거니까 주의해서 잘 보관하세요!
https://huggingface.co/settings/tokens
그럼 준비 끝~
2. 레포지토리 복제
git clone https://github.com/FurkanGozukara/stable-diffusion-xl-demo
이제 익숙하시죠? github 저장소에서 코드를 싹 복제해오는 겁니다. 복제했으면 stable-diffusion-xl-demo 폴더로 들어갑니다. 그담에 파워쉘이든 명령프롬프트cmd든 실행합니다. 터미널에 차례대로 아래 명령어를 입력합니다.
python -m venv venv
cd venv
cd scripts
.\activate
cd.. cd..
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install xformers==0.0.21.dev557
pip install -r requirements2.txt
자 착착 진행 다 됐죠?
그다음 app2.py 파일을 메모장으로 엽니다.
그리고 아까 허깅페이스에서 복붙해서 가지고 있던 token 있죠? 뭐 이런 거요. hf_jALBaskdhnasuihy8u21 그거를 "your token" 이 부분에 넣어줍니다. 이렇게요.
model_dir = os.getenv("SDXL_MODEL_DIR")
access_token = "hf_jALBaskdhnasuihy8u21"
이제 마지막! 으로 다시 메모장을 엽니다.
그다음 아래에 있는 내용을 넣어줍니다.
두 갠데, 위에 거는 저처럼 VRAM이 간당간당하신 분들용... 아래 거는 비싸고 좋은 고사양 컴터 쓰시는 분들용입니다. 둘 중 하나 내용 복붙해주세요. max_split_size_mb:128이 저사양, 256이 고사양입니다~
@echo off
set VENV_PATH=venv\Scripts\activate.bat
call "%VENV_PATH%"
set PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128
set ENABLE_REFINER=false
python app2.py
pause
@echo off
set VENV_PATH=venv\Scripts\activate.bat
call "%VENV_PATH%"
set PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:256
set ENABLE_REFINER=true
python app2.py
pause
자 그다음 이 파일을 run.bat 라는 이름으로 저장합시다.
이제 뻔하죠?
run.bat 파일을 실행합시다!
안 되면 이렇게 입력해서 실행~
.\run.bat
그럼 그냥 모델이니 뭐니 다운받느라고 시간 좀 잡아먹을 겁니다. 그렇게 다 끝나면 역시나-
Running on local URL: http://127.0.0.1:7860
이런 거 나올 겁니다. 그럼 저 주소를 브라우저에 복붙해서 접속하면 짠~
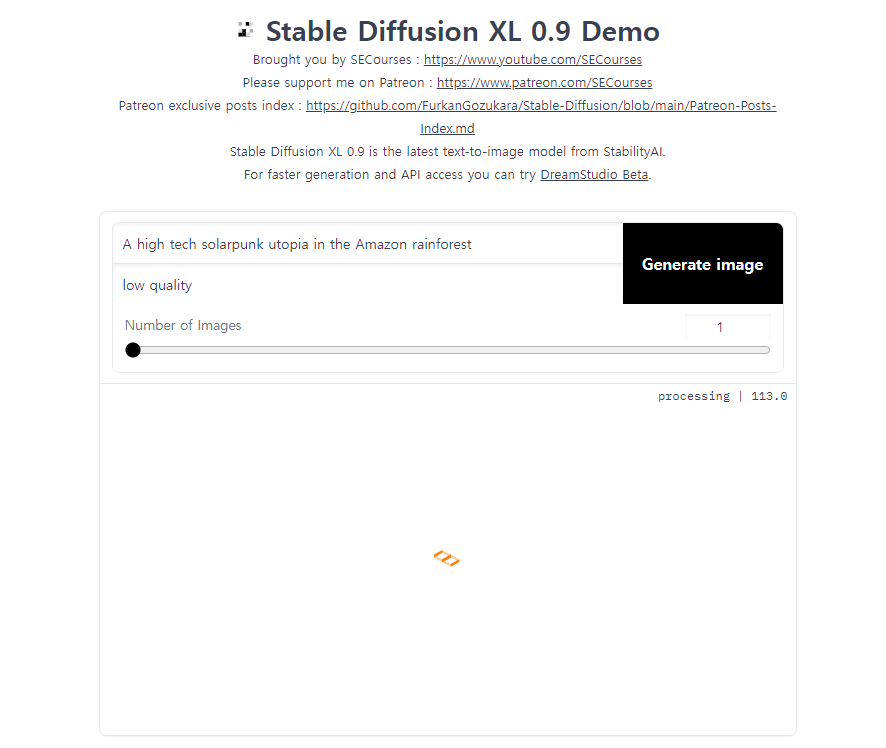
원래 쓰던 거보다 훨씬 심플하죠? 다른 기능은 다 빠지고 이미지 생성만 가능한 데모버전이라서 그렇습니다. 곧 뭐 제대로 나오면 그때 또 합시다. 자 그럼 대충 설정만 봅시다.
프롬프트 입력하는 게 두줄인데 위에는 positive 아래는 negative 입니다.
Number of images = Batch count 랑 똑같이 몇 장 렌더할 건지 결정
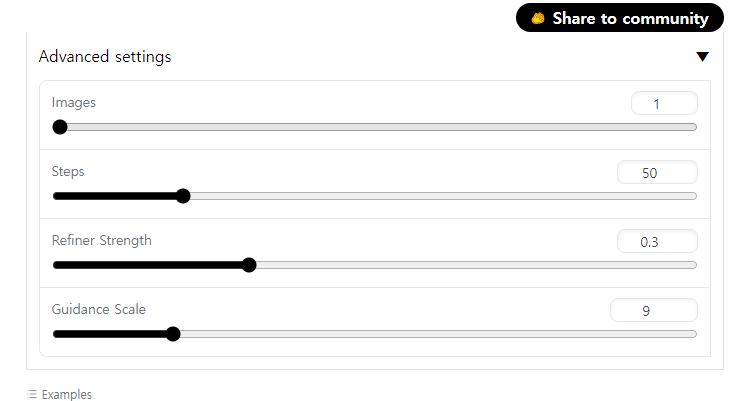
자 이제 advanced로 갑시다.
Images = Batch size랑 똑같이 한 번에 몇 장 렌더할 건지 결정
Steps = 아시죠? 샘플링하는 횟수잖아요. 너무 높아도 낮아도 별로고 적당히 주면 됩니다.
Refiner Strength = 이거는 이미지를 다시 한 번 만져주는 것이고, 그 강도를 설정합니다. 실제 생성하면 이미지가 만지기 전, 후 두 장 나옵니다. 아마도 이게 추가된 앙상블 모델의 기능을 이용하는 거 같네요??
Guidance Scale = 똑같습니다. 프롬프트 쎄게 따라갈 건지 참고만 할 건지.
뽑은 이미지는 하위 ouputs 폴더에 저장됩니다.
마지막으로 SDXL 0.9로 뽑은 이미지 한 번 보시고 마무리하겠습니다. (역시나 돌아가긴 하는데 엄청 오래걸리네요..ㅠ)


베이스 모델 퀄이 이정도라니...ㅎㄷㄷ;;;앞으로가 기대됩니다.
출처 - AI ARTWORK LAB : 네이버 카페 (naver.com)
AI ARTWORK LAB : 네이버 카페
stable diffusion 기반 이미지 생성을 비롯한 자연어처리 인공지능을 연구합니다. 쉽고~ 재미있게~
cafe.naver.com
'ai 만들어보기(feat ai artwork lab)' 카테고리의 다른 글
| [튜토리얼]아직도 돈 내고 chatGPT 쓰시나요? TEXT생성계의 스테이블 디퓨전! <oobabooga 깨부수기 -1-> (0) | 2023.07.11 |
|---|---|
| [튜토리얼]최신유행 따라잡기! QR코드를 꾸며보자!!! <img2img, ControlNet> (0) | 2023.07.10 |
| [튜토리얼]이미지의 크기를 내멋대로 늘려보자! <Upscale -1-> + GAN 이해해보기~ (0) | 2023.07.07 |
| [튜토리얼]신기방기! 이미지 속 인물의 나이를 멋대로 바꿔보자! <Text Inversion 깨부수기 -1-> (0) | 2023.07.05 |
| [튜토리얼]인공지능 생성이미지 인물의 포즈를 내 멋대로! <ControlNet 깨부수기 -2-> (0) | 2023.07.04 |