전에 올린 deforum으로 동영상 만들기는 언급했듯이 몰핑이나 트랜지션 효과에 가깝기 때문에 진짜 '영상'을 만든다고 하기에는 살짝 애매한 감이 있었습니다. 생성 방식도 바뀔 이미지에 대한 프롬프트를 입력하는 식이었죠. 그런데 이번엔 진짜로! 레알로! '영상의 내용을 입력'해서 우리가 말하는 그 움직이는 프레임 '영상'을 만들 수 있는 방법을 공유합니다. 전에도 있던 건데 이번에 추가 훈련 모델이 나왔는데 엄청 업그레이드가 된 것 같아서 한 번 저도 테스트해보고자 올립니다!
결과물부터 보시죠...
아주 엄청나진 않지만, 제가 말한 찐 동영상을 뽑는다는 게 뭔지는 확실하게 와닿으셨을 겁니다. 프롬프트에 걍 바닷속 문어Octopus under the sea라고 쳤을 뿐인데 저런 '영상'을 뽑아냈다는 겁니다.
1. 확장기능extensions 및 모델model 설치
이제 확장기능 설치 정돈 기본이겠죠? 아래 주소를 복붙해서 설치합니다.
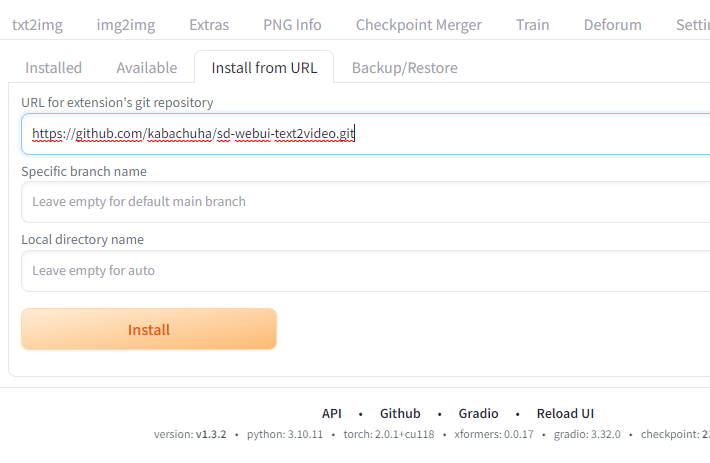
설치한 후에는 바로 하지 말고 추가작업이 필요합니다. 직접 폴더를 만들고 모델을 따로 받아와야 합니다. 이건 말 그대로 찐 비디오를 제작하는 것이기 때문에 이미지가 아닌 비디오를 트레이닝한 모델이 필요하기 때문이죠. 아래처럼 web UI 폴더의 models 폴더에 ModelScope/t2v 이렇게 폴더를 만듭니다.
stable-diffusion-webui/models/ModelScope/t2v
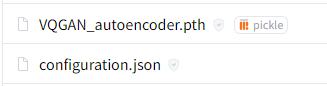
일단 위 이미지의 파일 두 개만 다운 받아서 t2v 폴더에 넣습니다.
그 다음 또 아래 주소로 갑니다.
https://huggingface.co/cerspense/zeroscope_v2_576w/tree/main/zs2_576w

위 이미지의 파일 두 개 다 다운받아서 t2v 폴더에 넣습니다. 이게 업그레이드 된 모델인데 576x320 해상도 버전입니다. 아래 주소로 가면 무려 1024x576 해상도로 뽑을 수 있는 모델을 다운받을 수 있습니다!
https://huggingface.co/cerspense/zeroscope_v2_XL/tree/main/zs2_XL
제가 고화질 영상을 제목에 쓴 건 이거 때문입니다. 예제 영상 보시죠.
놀랍지 않나요? 아직 부족한 게 사실이지만 이제 시작이라는 거! 앞으로가 기대됩니다. 단! 위 고화질 모델을 쓰면 그래픽 카드 열받는 건 각오해야 함..ㅋㅋ 일단 튜토리얼에선 테스트용으로 576x320 해상도 버전을 써보겠습니다. 설치가 끝났다면 스테이블 디퓨전을 실행합니다.
2. txt2video 설정
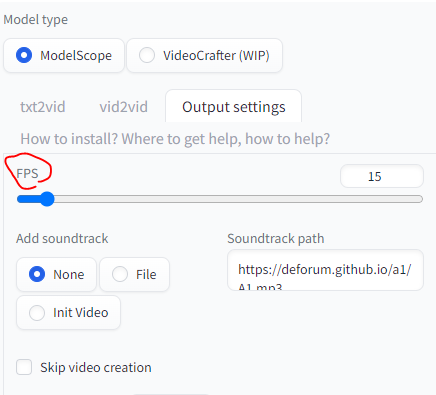
제대로 다 설치했으면 txt2video탭이 생겼을 겁니다. 선택합니다. 우선 아웃풋 세팅output setting부터 잡아봅시다. 딱히 손 댈 거 없고 FPS만 만집니다. 프레임인데 기본 15로 세팅돼있습니다. 영화는 24, TV는 30 알죠? 그런데 이 프레임 수가 늘어나면 당연히 부하가 걸리기 마련입니다. 집에서 대강 테스트하니까 걍 기본으로 갑시다.
자 이제 txt2vid 탭에서 본격적 세팅해봅시다. 모델 스코프ModelScope 선택하시고요.(VideoCrafter는 나중에) 사실 별로 할 게 없습니다. 위의 영상은 아래와 같은 세팅으로 뽑아냈습니다.
프롬프트(바닷속 문어Octopus under the sea)를 입력합니다. 아직 더 테스트를 해봐야겠지만 이미지처럼 이거저거 막 쓴다고 꼭 좋은 결과물이 나오는 것 같지는 않더군요. 여러분도 테스트 부탁드립니다. Negative Prompt는 기본설정된 것들 외에 FastNegativeV2라는 추가 text inversion을 썼는데 적용이 된 건지는 모르겠습니다.ㅎㅎ;;
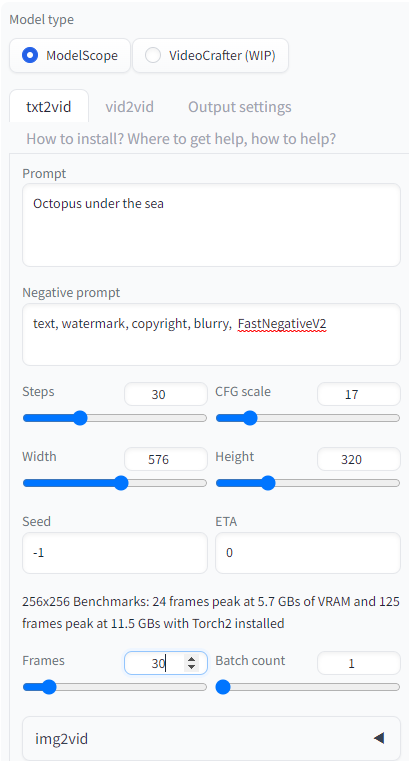
steps랑 CFG scale은 web ui 기본편을 참고 바랍니다. 중요한 건 Width랑 Height를 우리가 적용한 모델에 맞게 선택해야 양호한 결과물을 얻을 수 있다는 겁니다. 제가 이번에 적용한 model이 학습한 해상도가 576x320이니까 저렇게 세팅을 해줍니다. 벌써 비디오램 얼마 쓸 거라고 으름장을 놓고 있습니다. 개무섭ㅎㄷㄷ
또 만질 건 전체 프레임frames입니다. 아까 아웃풋에서 15를 설정했고, 여기서 30이니까 2초짜리 영상이 나올 겁니다. 여기까지 완료했으면 바로 생성버튼을 누릅니다. 그럼 짜잔~
완성했습니다. deforum의 효과만 못하죠. 더하여 이 정도 수준의 영상으로 뭘 할 수 있을까? 할 수도 있겠지만~ 컴퓨터 자원과 인공지능, 모델은 하루가 멀다하고 진보하고 있으니 역시나 앞으로가 더 기대가 됩니다. 이미 1024x576까지는 왔죠.
내 컴퓨터가 슈퍼컴퓨터 수준이다 하시는 분들 1024고화질 모델로 테스트 부탁드립니다~ 그럼~
AI ARTWORK LAB : 네이버 카페
stable diffusion 기반 이미지 생성을 비롯한 자연어처리 인공지능을 연구합니다.
cafe.naver.com
'ai 만들어보기(feat ai artwork lab)' 카테고리의 다른 글
| [튜토리얼]인공지능 생성이미지를 내 의도에 가깝게 만드는 강력한 도구! <ControlNet 깨부수기 -1-> (0) | 2023.07.03 |
|---|---|
| [튜토리얼]사진은 지겹다! 인공지능으로 예술적인 영상을 만들어보자! <deforum 깨부수기 -1-> (0) | 2023.07.03 |
| [이해해보기]stable diffusion은 대체 어떤 과정을 거쳐 문자(자연어)를 이미지로 토해내는가!? 3줄 요약 있음 (0) | 2023.06.29 |
| [튜토리얼]본격적으로 인공지능 이미지 생성해보기 (Stable diffusion web UI 사용법) -1- (0) | 2023.06.27 |
| [튜토리얼]100% 무료?? 구글 colab으로 인공지능 이미지 생성하기! (0) | 2023.06.26 |