이제 설치까지는 끝났으니까 간략하게 stable diffusion web UI(automatic1111 기준)에 대해서 알아봅시다. 역시나 기본적인 부분은 stable-diffusion-art.com에서 나온 내용을 기반으로 설명합니다. 요즘에 하도 이런저런 기능들이 많다 보니까 점점 더 복잡해지는 느낌이 들긴 하는데, 아무튼 일단 기본적인 거부터 차례로 알아갑시다. 일단 여기 나온 것들만 이해하고 써도 web UI뿐만 아니라 다른 웹서비스도 사용하는데 큰 지장은 없으리라 봅니다.
가장 기본적인 txt2img 탭을 살펴봅시다.
말 그대로 텍스트, 프롬프트(prompt)를 입력하면 이미지를 토해내는 자연어 처리 모델 바로 그겁니다. 얼마나 좋은 세상인지 정말, 단 영어로 입력하셔야 합니다. 아래쪽 negative prompt는 내 이미지에 적용하면 안 될 것들을 써넣는 겁니다. 예를 들어 손이 네 개(four hands), 저품질(low quality) 뭐 이런 겁니다. 그냥 기본 설정 상태에서 아무거나 입력해보고 생성해보면 바로 알 수 있습니다..
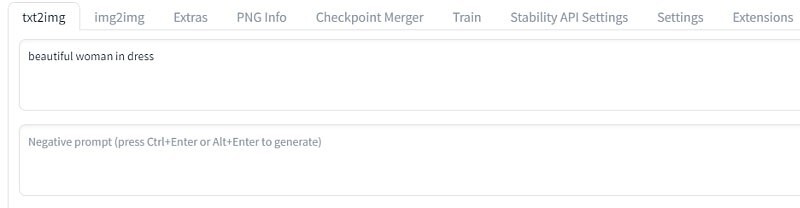
이제 아래 쪽의 다른 설정을 살펴봅시다. 뭐가 많습니다.
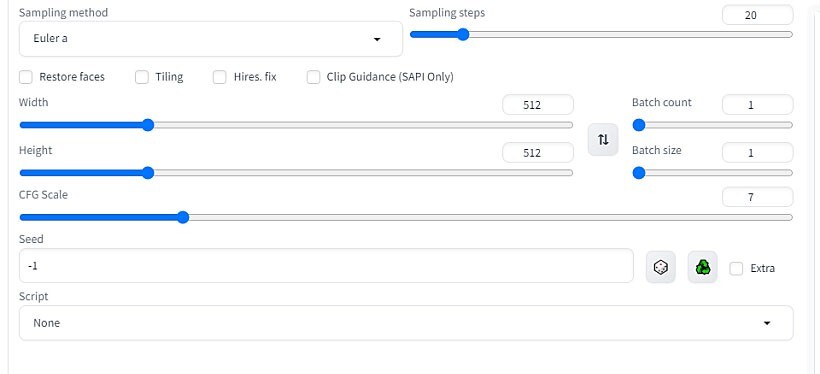
이게 사실 원리까지 깊이 알면 더 좋겠지만, 우리는 다른 거 제쳐두고 일단 빨리 예쁜 그림이나 뽑고 싶기 때문에 걍 기능적인 측면에서 최소한의 필요한 지식 위주로 간단하게 정리해봅시다.
sampling method 는 어떤 방식으로 이미지를 생성할 것인지 선택하는 겁니다. 그 샘플링 방식이란 게 어찌 보면 또 핵심적인 부분이라 깊이 알면 좋겠지만, 일단 또 넘어갑니다. 단순히 말하자면 무분별한 노이즈 상태에서 고양이 그림을 만든다고 할 때 그 노이즈를 제거해가는 방식입니다. 클릭해보면 쭉 이거저거 많이 나올 겁니다. 이거는 사실 정답이 없다고 할 수 있습니다. 프롬프트와 이런저런 변수에 따라서 각 샘플링 방식이 비슷하면서도 미세하게 다른 결과를 냅니다.

보다시피 개취임
sampling steps는 이 노이즈 제거하면서 최종이미지까지 도달하는 과정의 단계 횟수를 정합니다. 중요한 건 많다고 무조건 좋은 건 아닙니다. 아래 그래프를 보면 샘플링 단계 횟수에 따라서 이미지 품질(낮을수록 좋음)이 변하는 과정을 보여줍니다.

보면 알겠지만 30 이후로는 크게 품질이 변하지 않는 걸 알 수 있고 DDIM의 경우 오히려 20에 가장 좋은 품질을 보여주기도 합니다. 20~30 정도면 적당한 수치라고 볼 수 있습니다.
width와 height는 말 그대로 출력할 이미지의 크기를 결정하는 건데, 내가 사용하는 모델이 학습한 이미지 사이즈가 가장 좋은 결과물을 낼 수 있는 사이즈입니다. 각 모델 별로 학습된 이미지의 크기가 다른데 stable diffusion 1.5의 기본 모델은 512X512 사이즈가 최적사이즈입니다. 각 모델들 보면 각기 최적 사이즈 설정이 다 제시돼 있으니 참고하심 됩니다.
batch count는 한 번 생성할 때 이미지를 몇 번 생성할 지 결정하고
batch size는 한 번에 몇 장의 이미지를 생성할지 결정합니다.
예를들어 batch count 가 2이고 batch size가 2면 한 번에 2장씩 2번, 총 4장의 이미지를 만들어 냅니다. 프롬프트를 테스트할 때는 batch size를 2-4정도로 두고 한 번에 여러 장씩 보면서 하는 게 좋긴 합니다. 그런데 만약 내 자원이 영 별로인 경우는 1장씩만 해도 무방하긴 합니다.
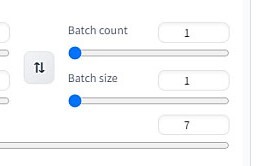
CFG(classifier free guidance) scale은 다른 이미지 생성 웹서비스 같은데 보면 Guidance scale이라고도 많이 씁니다. 즉 프롬프트 강도를 지정하는 겁니다. 이게 강해질 수록 내가 프롬프트에 쓴 텍스트대로 나오도록 한다-는 건데 이렇게 정리해둔 자료가 있습니다.

1 - 대부분 프롬프트를 무시.
3 – 더 창의적.
7 - 프롬프트를 따르는 것과 자유 사이의 균형.
15 – 프롬프트를 더 많이 준수.
30 – 프롬프트를 엄격히 따름.
web UI기준 저렇지만 원래 스테이블 디퓨전은 999까지도 설정 가능하다고 합니다. 그럼 어? 걍 엄청 쎄게 해야 내 의도를 반영하는 거 아냐? 생각하겠지만 전혀 아닙니다. web UI에서 30까지 제한한 이유가 있죠. 7-9 정도가 적당합니다. 아래 예제(prompt: cat in cage)처럼 너무 낮으면 진짜 개무시해서 지멋대로에 가까운 이미지가 나오고, 너무 높은 경우 채도(saturation)가 너무 높고 왜곡된, 품질이 구린 이미지가 나올 수 있습니다.

근데 이것도 대략 그렇다는 거지 무조건 이렇다-고 할 수는 없습니다. CFG scale은 또한 쉽게 말해 단독변수가 아니라 sampling method와 steps의 종속변수라서 두 값이 변하면 함께 값이 달라질 수 있습니다. 따라서 sampling method 및 steps와 함께 이것저것 적용해보는 과정이 필요할 수 있겠습니다.
이제 prompt 아래 쪽 체크란을 봅시다.
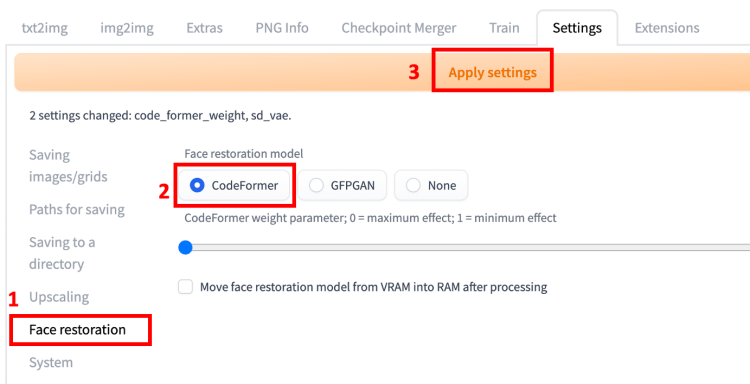
restore face는 말 그대로 얼굴의 결함을 복원하도록 추가 모델을 적용하도록 합니다. 해보심 아시겠지만 얼굴이 뭉개진 이미지가 자주 생성되는 걸 알 수 있습니다. 요걸 제대로 바로 잡아주는 건데 설정에서 미리 얼굴 복원 모델을 지정해야 합니다. settings 탭으로 이동합니다. restore face 섹션에서원 모델을 선택합니다. CodeFormer가 좋다고들 합니다. 효과를 극대화하려면 CodeFormer 가중치를 0으로 설정합니다. 1에 가까울수록 약해지는데 이것도 역시 시행착오가 필요한 부분입니다. 아예 체크하지 않는 게 나을 때도 있습니다.
Tiling은 이미지를 반복해서 생성할 수 있습니다. 이건 뭐 단어 그대로입니다. 타일링. 근데 솔직히 써본 적은 없습니다.
hires.fix는 역시나 단어 그대로 고화질 보정을 의미합니다. upscaler를 사용하겠다는 겁니다. 원체 기본 모델 이미지 자체가 작다 보니까 upscale은 필수라고 봅니다. 그만큼 upscaler모델도 아주 다양합니다. 체크하면 아래처럼 설정값이 나옵니다.
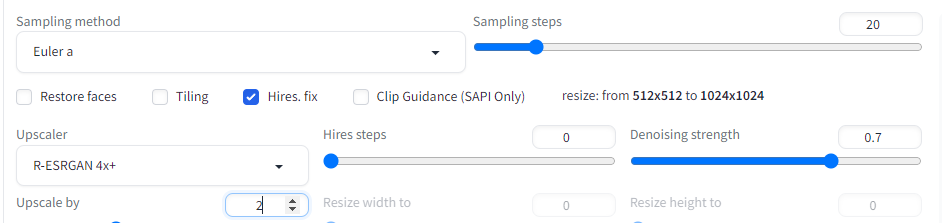
일단 Upscaler를 선택해야 합니다. 말했듯 다양한 모델이 있고, 자세한 건 일단 생략하고 넘어갑니다.
파라메터만 좀 보면 Upscale by는 현재 사이즈에서 몇 배나 키울 건지 택합니다. 당연히 커질수록 시간도 오래걸리고 퀄은 하락합니다.
Hires steps는 위의 샘플린 단계 횟수랑 비슷한 개념입니다.
denosing strength는 말그대로 업스케일 하면서 생기는 노이즈를 없애는 건데 0.5 이상은 되어야 제대로 나옵니다. 근데 실제로 upscale 작업은 이 Hires.fix 를 체크해서 하는 것보다는 일단 걍 기본 오리지널 이미지를 뽑은 다음, 아래 보이는 extras탭으로 가서 따로 좀 더 세세하게 작업하는 걸 권합니다. upscale 부분은 upscaler를 포함해 따로 튜토리얼을 정리해봅시다.

seed는 내가 이미지를 뽑았는데 마음에 든다 싶으면 그걸 그대로 계속 뽑아내고 싶을 때 씁니다. seed값은 내 멋대로 입력할 수도 있고 랜덤으로 부여할 수도 있습니다. 프롬프트가 같고 시드도 같으면 같은 이미지를 뽑아낸다는 겁니다. but 당연한 말이지만 sampling method나 steps, model, LoRa 등등을 다르게 적용하면 이미지가 조금씩 달라집니다. 그러니까 seed 값을 그대로 두고 다른 변수를 바꾸면 내 마음에 드는 하나의 기본 이미지를 가지고 여러 느낌으로 뽑아볼 수 있다는 겁니다. 테스트 해보면 seed값을 랜덤(-1)으로 두는 경우와 지정하는 경우 차이를 쉽게 알 수 있습니다.

script는 아래처럼 프롬프트나 위의 설정값 여러 개를 한꺼번에 비교해볼 수 있는 표 같은 걸 뽑아낼 수 있는 추가 기능입니다. 이건 이거저거 테스트해볼 때 유용한 기능인데 당장 이미지를 뽑는데 중요한 건 아니니까 간단하게 여기까지만 하고 패스.

글이 너무 길어질 거 같으니 img2img 및 inpaint 이거저거 다른 기능들은 또 다른 글로 정리해 넘겨보겠습니다.
근데 이 정도만 알아도 일단 기본적으로 이미지 뽑아보는데는 전혀 지장이 없을 겁니다. 또 이런 설정값 만큼 중요한 건 prompt를 얼마나 잘 쓰느냐인데 그게 더 급할 거 같아서 요거 2편보다 그걸 먼저 써보려고 합니다. 그럼 이만~
출처 - AI ARTWORK LAB : 네이버 카페 (naver.com)
AI ARTWORK LAB : 네이버 카페
stable diffusion 기반 이미지 생성을 비롯한 자연어처리 인공지능을 연구합니다.
cafe.naver.com
'ai 만들어보기(feat ai artwork lab)' 카테고리의 다른 글
| [튜토리얼]사진은 지겹다! 인공지능으로 예술적인 영상을 만들어보자! <deforum 깨부수기 -1-> (0) | 2023.07.03 |
|---|---|
| [튜토리얼]충격과 공포! 인공지능으로 찐 레알 ''고화질 동영상'' 만들기!!!! <text2video -1-> (0) | 2023.06.30 |
| [이해해보기]stable diffusion은 대체 어떤 과정을 거쳐 문자(자연어)를 이미지로 토해내는가!? 3줄 요약 있음 (0) | 2023.06.29 |
| [튜토리얼]100% 무료?? 구글 colab으로 인공지능 이미지 생성하기! (0) | 2023.06.26 |
| [튜토리얼] 100% 무료 내 컴퓨터(windows)로 인공지능 이미지 만들기 (6) | 2023.06.21 |